用 Dify 构建一个简单的大语言模型(LLM)驱动的应用程序
1. 概述
Dify 是一个开源的大语言模型(LLM)应用开发平台。提供从 Agent 构建到 AI workflow 编排、RAG 检索、模型管理等能力,轻松构建和运营生成式 AI 应用。
Dify 可以为开发人员节省大量时间,使他们能够专注于业务需求,快速构建生产级的生成式 AI 应用。
Dify 这个名字来自 Define + Modify,指的是定义并不断改进我们的 AI 应用程序。
本文旨在初步探索了解 Dify 可以做到哪些事情,以及什么样的业务需求可以由 Dify 来帮助我们去完成。
2. 假设的一个业务场景
北京市公共数据开放平台 是一个面向公众的政府数据平台。这些数据(见下图)与我们生产生活密切相关,它们是以文件或接口形式对外开放。信息种类和数量庞杂,要想了解某一类信息,需要通过接口获得数据,再对数据进行加工处理。
例如:北京市统计局提供的农林牧渔业总产值,见下图
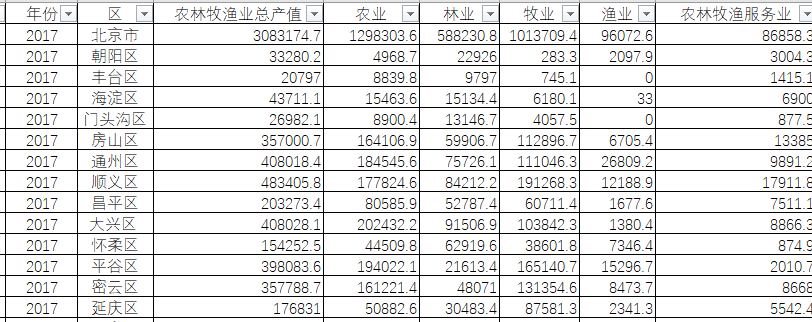
可以利用 Dify 创建 AI 交互应用,自动获得我们要的数据,并利用 LLM 来帮助我们理解分析数据。
3. 最终实现的功能
创建一个 ChatFlow 应用,当启动时,可以有两个查询选项。(见下面视频演示)
分别是:
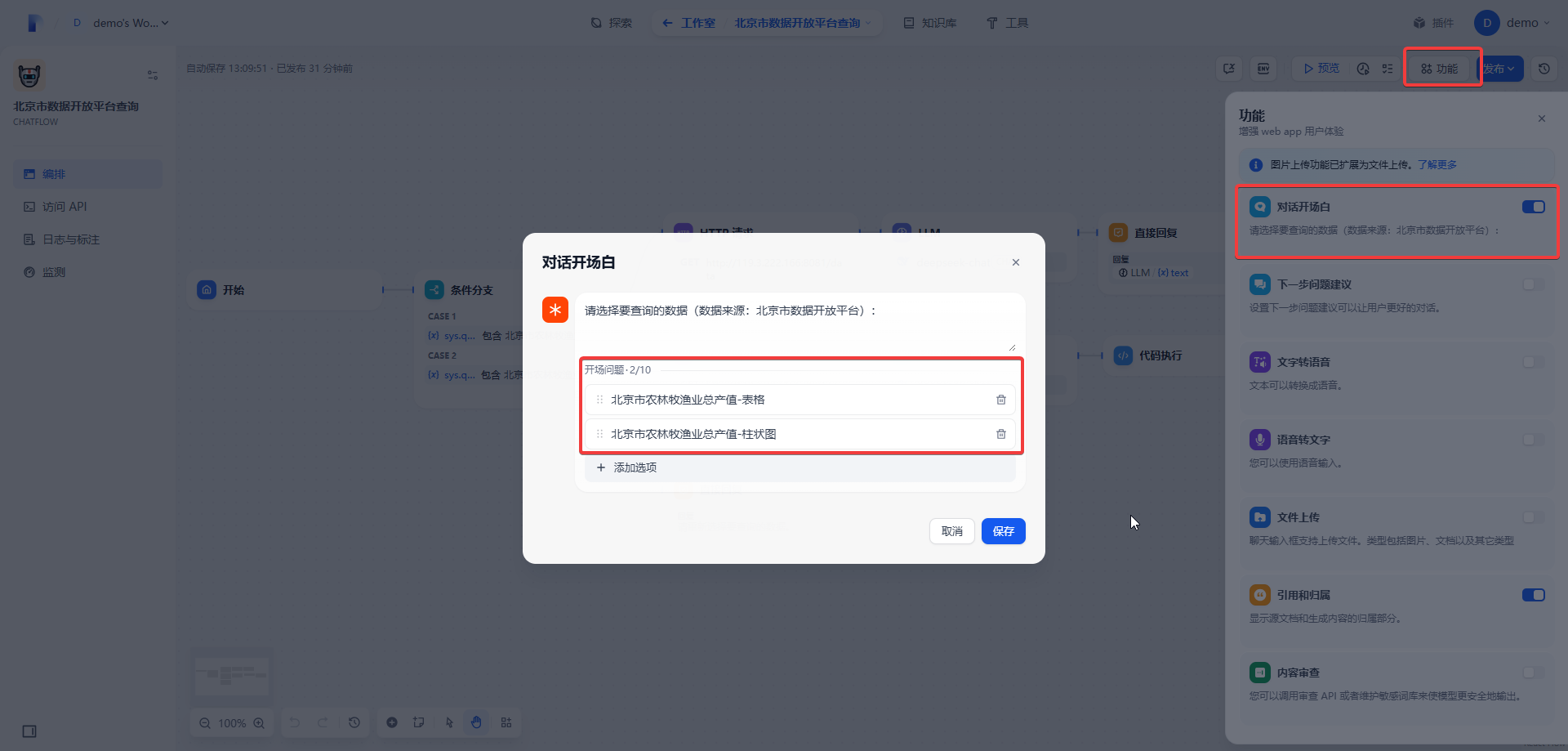
- 北京市农林牧渔业总产值-表格
- 北京市农林牧渔业总产值-柱状图
在这个例子中 LLM 的作用是将 API 接口调用获得的数据进行抽取,因为接口返回的数据集中既包括北京市的总体数据也包括了各个区的数据。
我们的业务需求是:
- 当查询 北京市农林牧渔业总产值-表格 时,只要北京市的历年农林牧渔业的总产值和分项产值,各个区的历年数据是不需要的。
- 当查询 北京市农林牧渔业总产值-柱状图 时,只要北京市的历年农林牧渔业的总产值,各个区的总产值和各分项产值是不需要的。
北京市农林牧渔业总产值 Excel 文件。Download
当查询 北京市农林牧渔业总产值-表格 时,结果如下图。

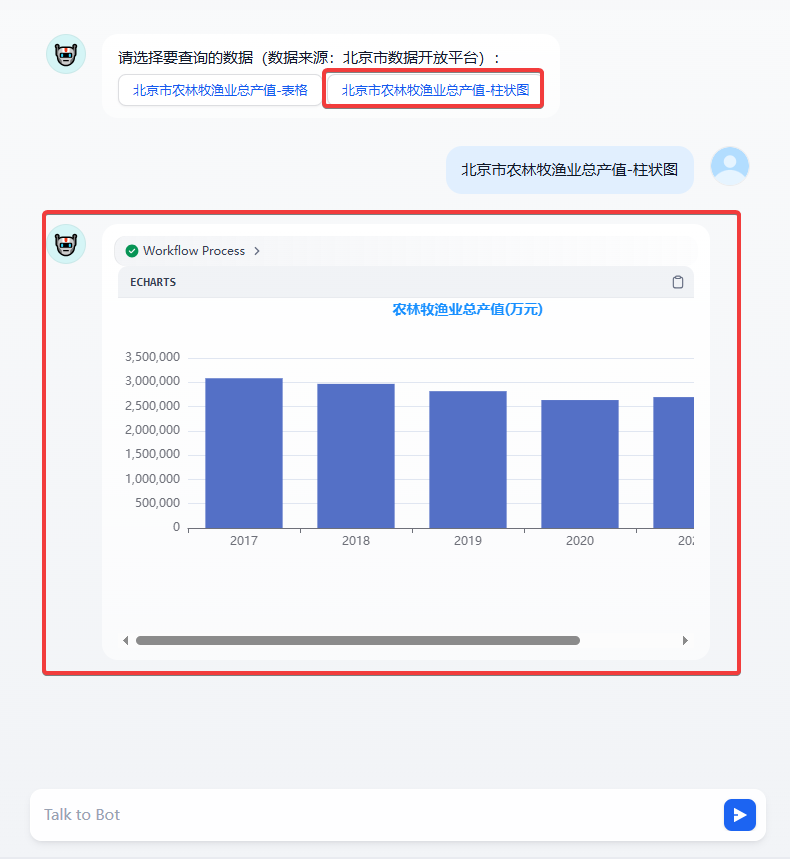
当查询 北京市农林牧渔业总产值-柱状图 时,结果如下图。
4. 准备 Dify 测试环境
测试环境为华为云服务器 Ubuntu 22.04 server 64bit(2核 4G内存)配置安全组入规则,允许 80 端口。安装 Docker 和 Docker Compose(v2)
从项目库下载社区 Release 版 https://github.com/langgenius/dify 解压上传到 Ubuntu 服务器上
# 进入 Dify 源代码的 Docker 目录
cd dify/docker
# 复制环境配置文件
cp .env.example .env
# 启动 Docker 容器
docker compose up -d
第一次访问 http://服务器IP地址 需要设置管理员邮箱和密码。
5. 准备后端数据服务接口
为了简单和方便测试,这里没有使用北京市公共数据开放平台,而是使用了一个模拟的后端接口。
使用了一个开源的项目 JSON-Server,并将 json-server 在 docker 环境中运行。
首先,创建一个 Dockerfile 文件,并拷贝下面内容。
FROM node:latest
RUN npm install -g json-server
WORKDIR /data
VOLUME /data
EXPOSE 80
ADD run.sh /run.sh
ENTRYPOINT ["bash", "/run.sh"]
CMD []
创建一个 run.sh 文件,并拷贝下面内容。
#!/bin/bash
args="$@"
args="$@ -p 80"
file=/data/db.json
if [ -f $file ]; then
echo "Found db.json, trying to open"
args="$args db.json"
fi
file=/data/file.js
if [ -f $file ]; then
echo "Found file.js seed file, trying to open"
args="$args file.js"
fi
json-server $args
这个 db.json 文件包含我们的测试数据 Download
在 Ubuntu 服务器的 home 目录下创建 docker-json-server 目录,将三个文件 Dockerfile , run.sh , db.config 上传到这个目录下,如下图所示。
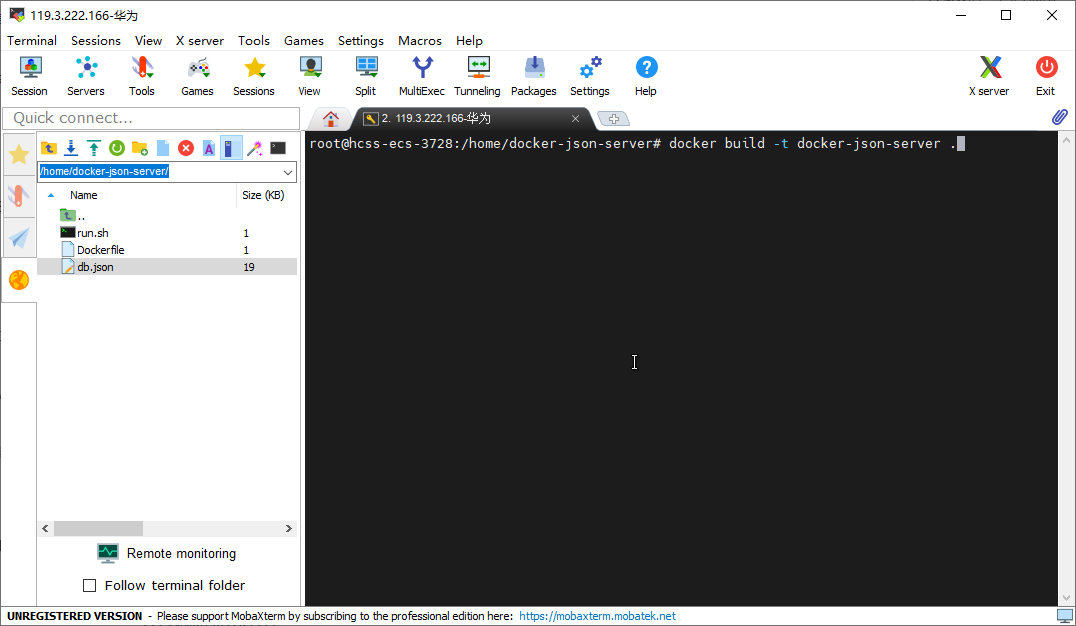
进入到这个目录下执行下面命令,构建 json-server 的 docker 镜像。
docker build -t docker-json-server .
执行下面命令,启动 json-server docker 运行时,这里使用 8081 端口。需要打开云服务器的安全组规则,允许 8081 的访问。
docker run -d --name docker-json-server -p 8081:80 -v /home/docker-json-server/db.json:/data/db.json --restart=always docker-json-server
打开浏览器访问 http://服务器IP:8081/data 可以看到数据,表示我们后端服务模拟的数据接口可以使用了。

6. 在 Dify 中接入 DeepSeek
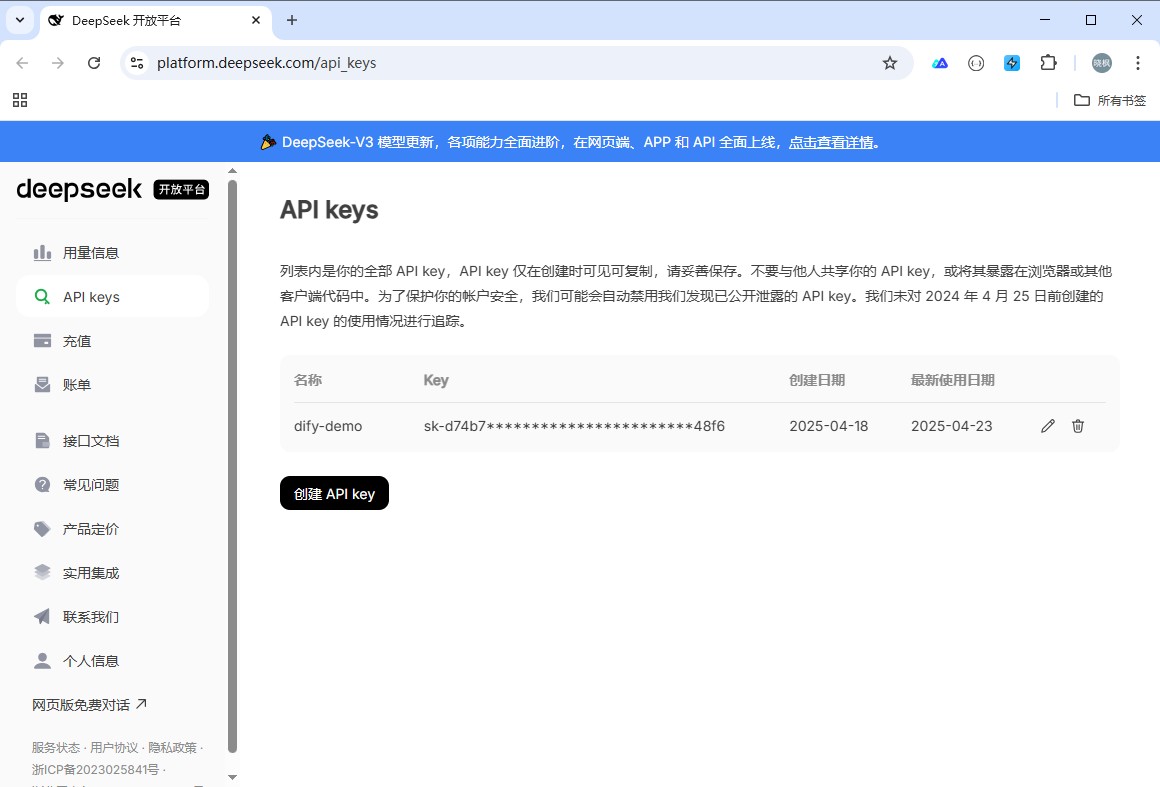
这里使用 DeepSeek 作为模型供应商接入 Dify ,需要申请 API key,打开 DeepSeek API 开放平台,创建 API Key
如下图所示:
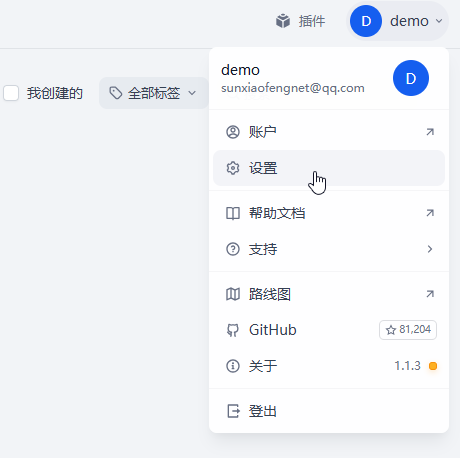
进入 Dify 界面,点击设置,如下图
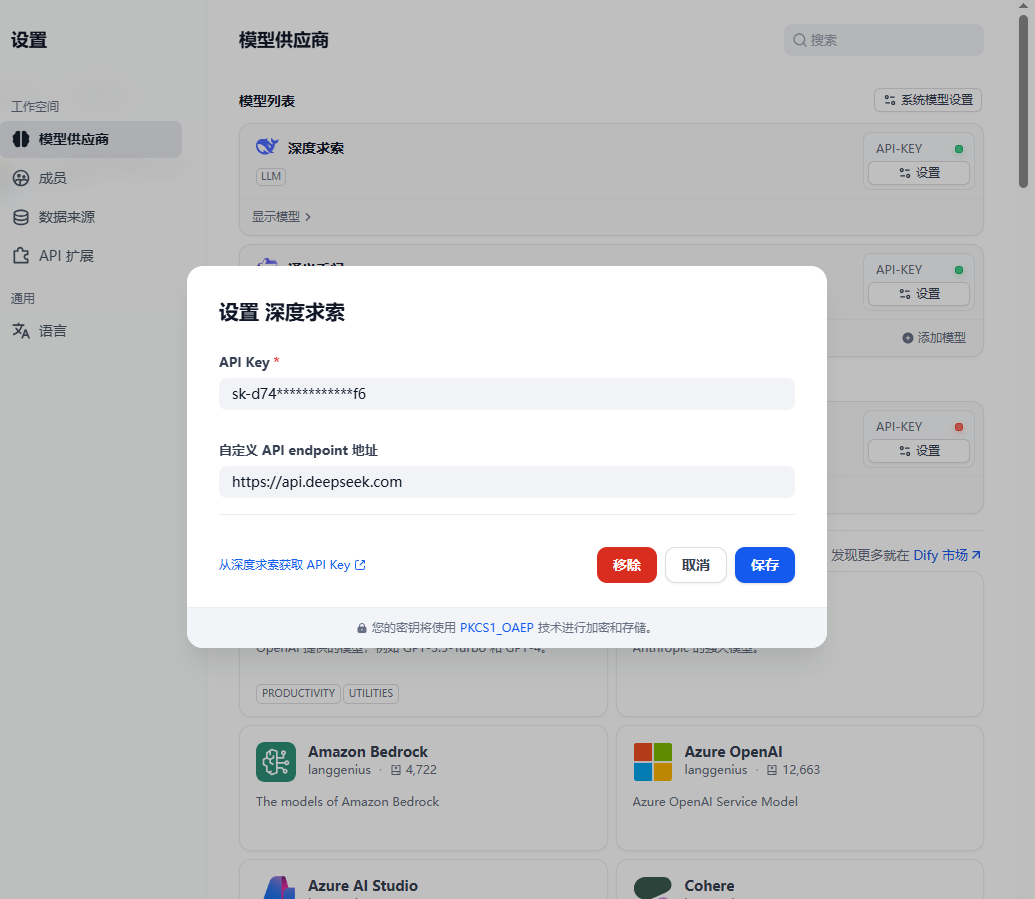
在模型供应商中搜索并安装深度求索,设置刚才创建的 API key,如下图所示。
DeepSeek 模型使用价格,参见 价格详情
如果选择本地自建模型,可以选择 Ollama 。它是开源工具,专为无缝部署大语言模型(LLM)而设计。
可参考在 Dify 接入 Ollama 部署的本地模型
7. 在 Dify 中创建应用
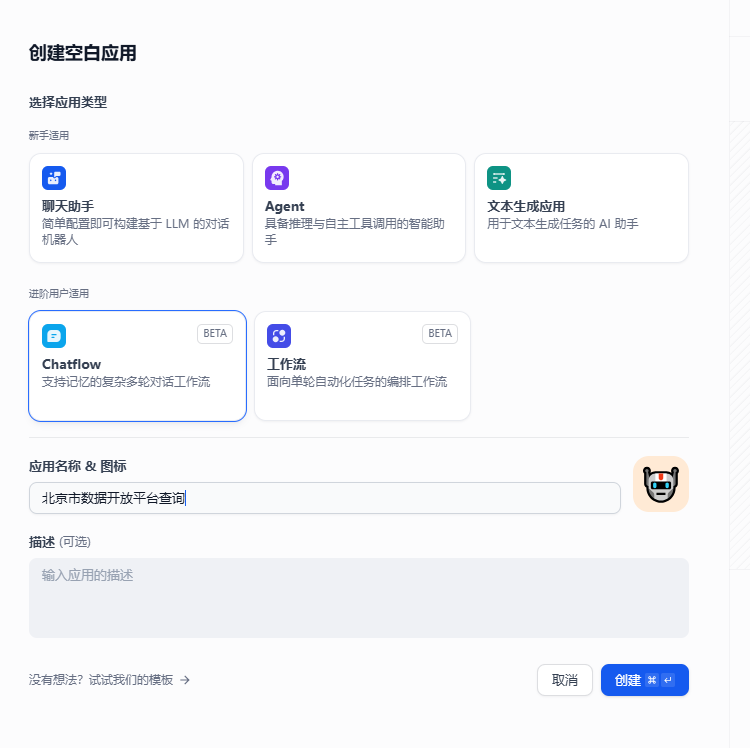
打开 http://服务器IP 登录到 Dify 后,在主页中,点击创建空白应用。选择 Chatflow ,输入应用名称 北京市数据开放平台查询
下图是创建完成的所有流程节点。
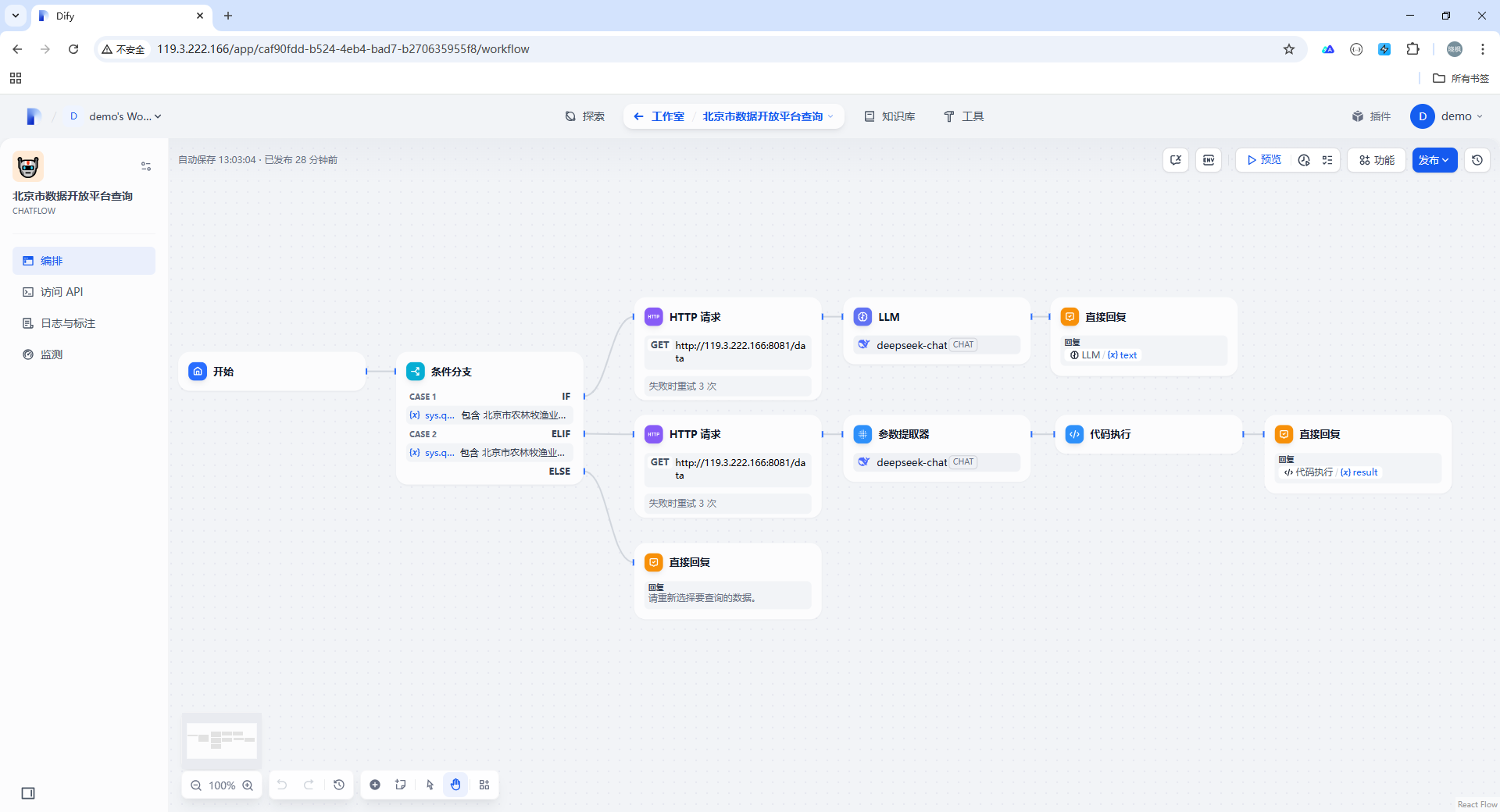
下面依次介绍各个节点。
首先,要设置两个开场问题选项,如下图所示。
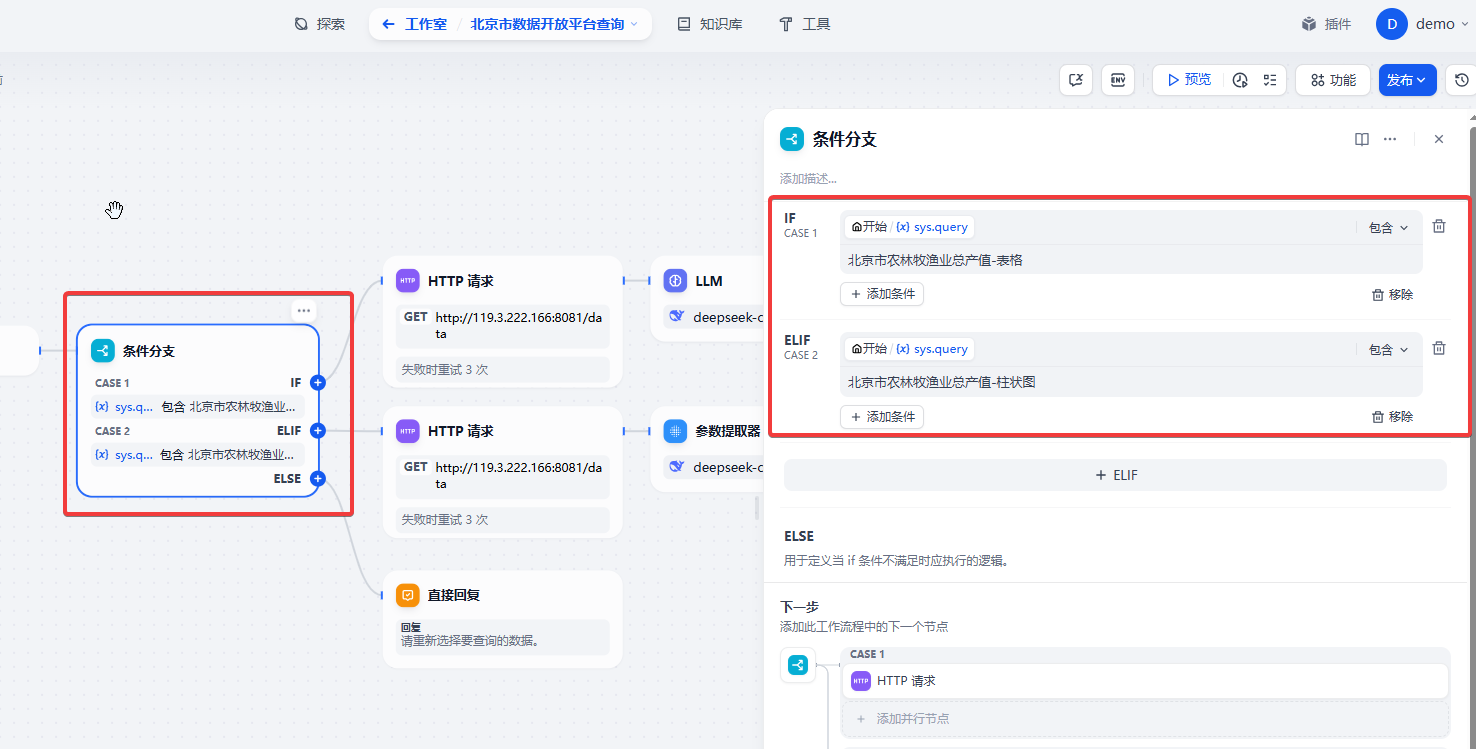
条件分支节点
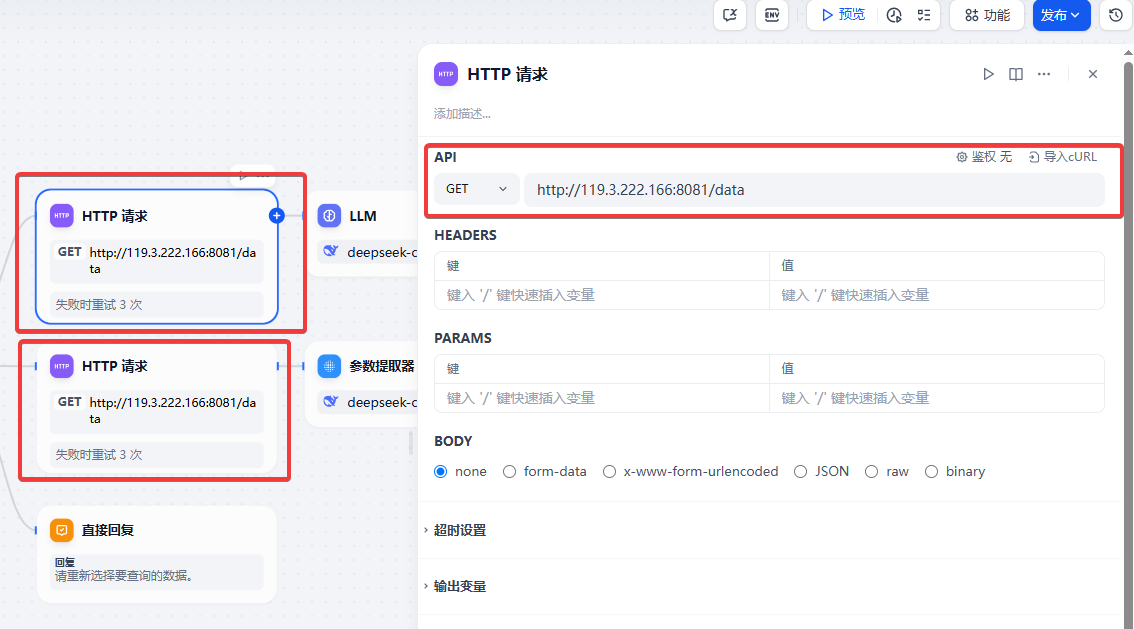
两个 API 请求节点,两个节点调用 API 地址一样。
条件分支下的回复节点

LLM 节点,将调用 API 获得的数据抽取出北京市的各项产值,并要求表格输出。
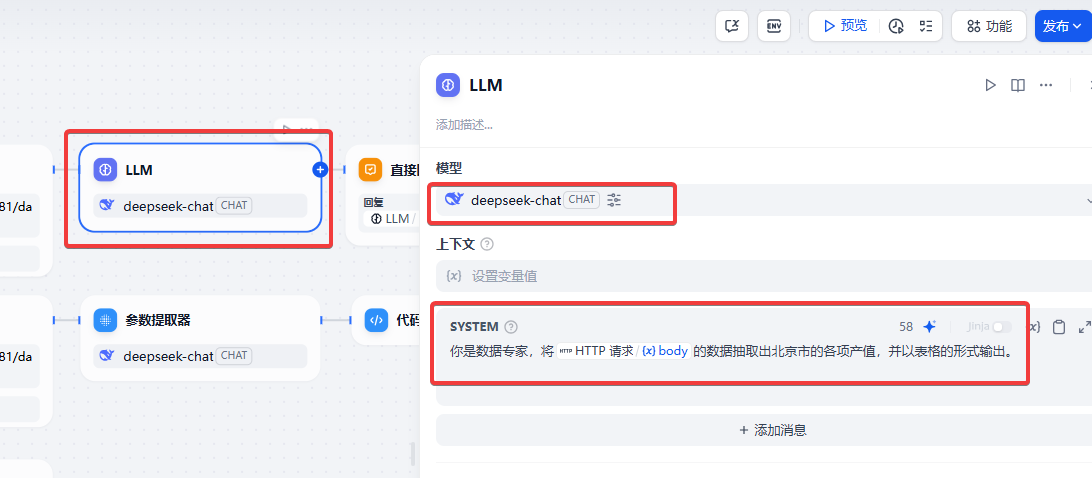
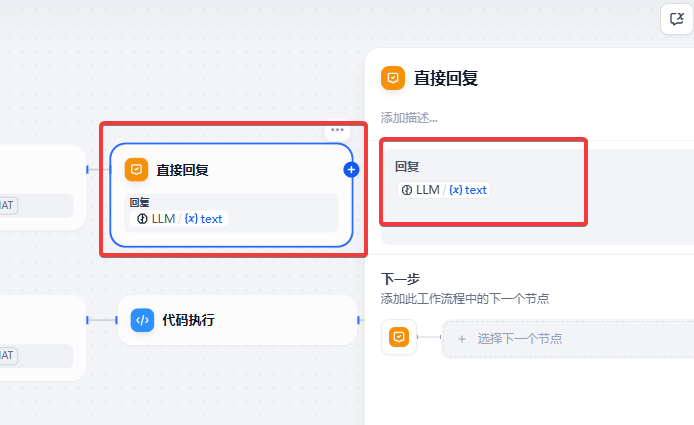
LLM 后面的回复节点。
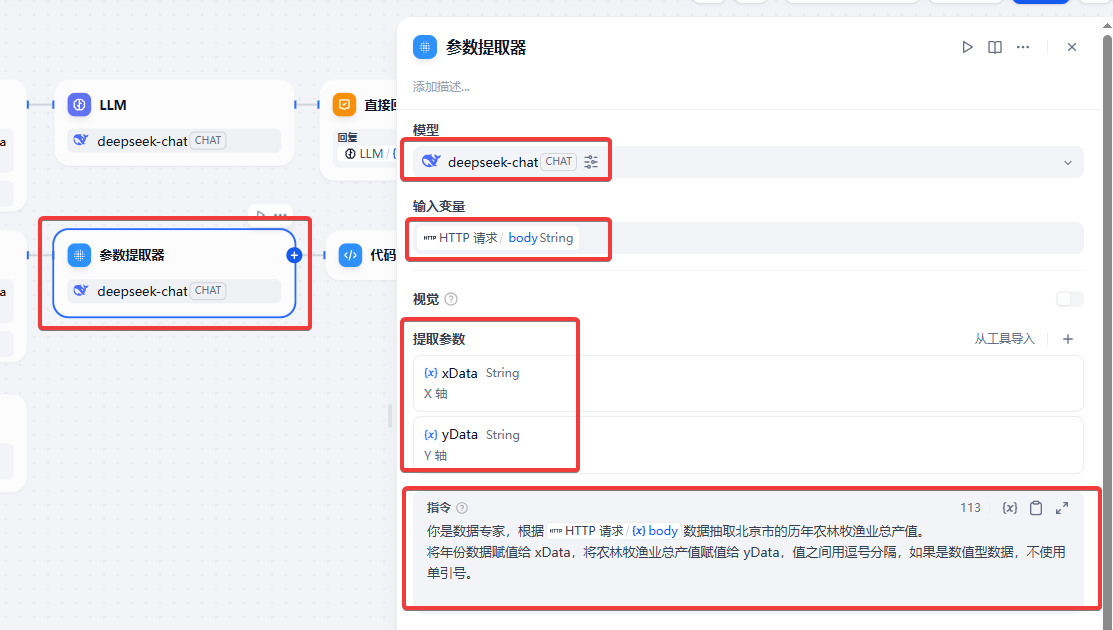
参数提取器节点,将调用 API 获得的数据抽取出北京市的历年农林牧渔业总产值,构造用于画柱形图的数据。
代码节点,用于生成柱形图
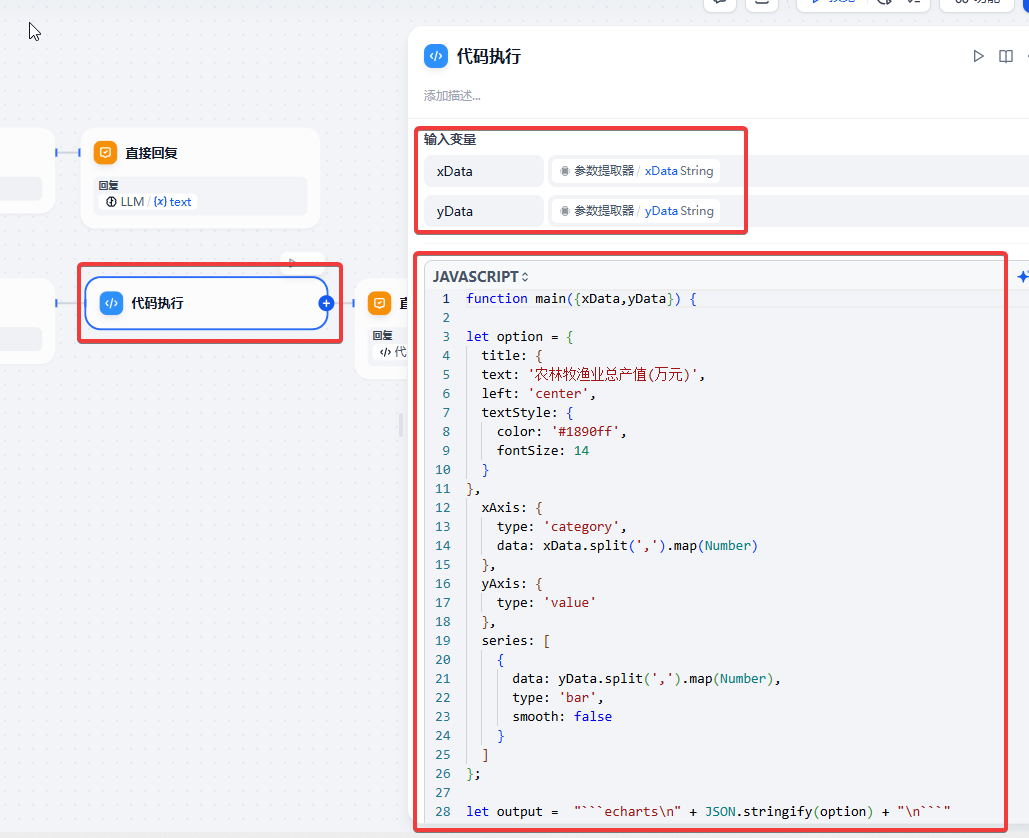
完整 javascript 代码段如下:
function main({xData,yData}) {
let option = {
title: {
text: '农林牧渔业总产值(万元)',
left: 'center',
textStyle: {
color: '#1890ff',
fontSize: 14
}
},
xAxis: {
type: 'category',
data: xData.split(',').map(Number)
},
yAxis: {
type: 'value'
},
series: [
{
data: yData.split(',').map(Number),
type: 'bar',
smooth: false
}
]
};
let output = "```echarts\n" + JSON.stringify(option) + "\n```"
return {
result:output
}
}
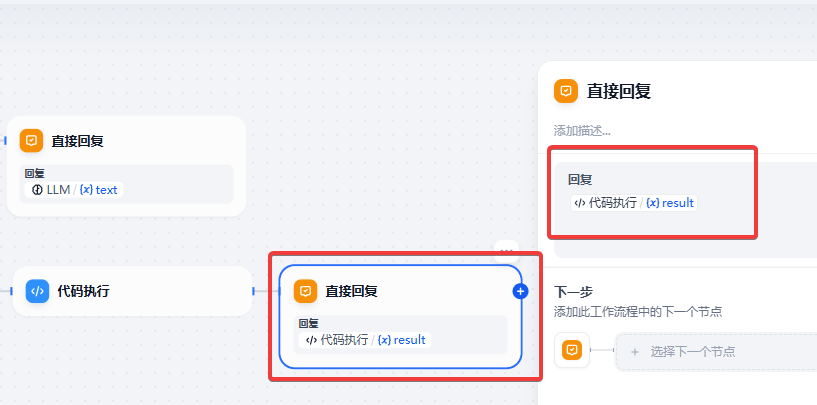
代码节点后的回复节点
8. 测试应用
当查询 北京市农林牧渔业总产值-表格 时,只显示北京市的历年农林牧渔业的总产值和分项产值,各个区的历年数据不在输出结果中。
- 当查询 北京市农林牧渔业总产值-柱状图 时,只显示北京市的历年农林牧渔业的总产值柱状图,各个区的总产值和各分项产值不体现在柱状图中。
9. 其它
本文仅简单演示了 Dify 的一些基础功能,Dify 还有一些其它的能力。
- 工作流中的代码节点仅适用于逻辑简单的情况。如果要实现更复杂的业务可以开发自定义的插件。
- 通过创建自定义的工作流并转换成工具组件,也可以实现处理流程逻辑的复用。
- 通过创建基于业务的知识库,可以结合信息检索和大语言模型(LLM)的生成能力,即 RAG (Retrieval-Augmented Generation 检索增强生成)能力。建立一个业务知识库适用于智能客服(基于企业文档问答)和医疗/法律问答(基于专业知识数据库)等场景应用。
10. 参考资料
[1] Dify 官网
[2] Dify Github
[3] 北京市公共数据开放平台
[4] 北京市公共数据开放平台-农林牧渔业总产值
[5] JSON-Server
[6] DeepSeek API 开放平台
[7] DeepSeek 价格详情
[9] Ollama
[10] 接入 Ollama 部署的本地模型